

The first method that we'll apply to our walking robot problem is A2C, which we experimented with in part three of the book. This choice of method is quite obvious, as A2C is very easy to adapt to the continuous action domain. As a quick refresher, A2C's idea is to estimate the gradient of our policy as
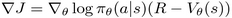
. The  policy is supposed to provide to us the probability distribution of actions given the observed state. The quantity
policy is supposed to provide to us the probability distribution of actions given the observed state. The quantity  is called a critic, equals to the value of the state and is trained using the Mean Square Error (MSE) between the critic return and the value estimated by the Bellman equation. To improve exploration, the entropy bonus
is called a critic, equals to the value of the state and is trained using the Mean Square Error (MSE) between the critic return and the value estimated by the Bellman equation. To improve exploration, the entropy bonus  is usually added to the loss.
is usually added to the loss.
Obviously, the value head of the actor-critic will be unchanged for continuous actions. The only thing that is affected is the representation of the policy. In the discrete cases that we've seen, we had only one action with several mutually exclusive discrete values. For such a case, the obvious...