

How ML engineers can get the most out of AWS
There are many services and capabilities in the AWS platform that an ML engineer can choose from. Professionals who are already familiar with using virtual machines can easily spin up EC2 instances and run ML experiments using deep learning frameworks inside these virtual private servers. Services such as AWS Glue, Amazon EMR, and AWS Athena can be utilized by ML engineers and data engineers for different data management and processing needs. Once the ML models need to be deployed into dedicated inference endpoints, a variety of options become available:
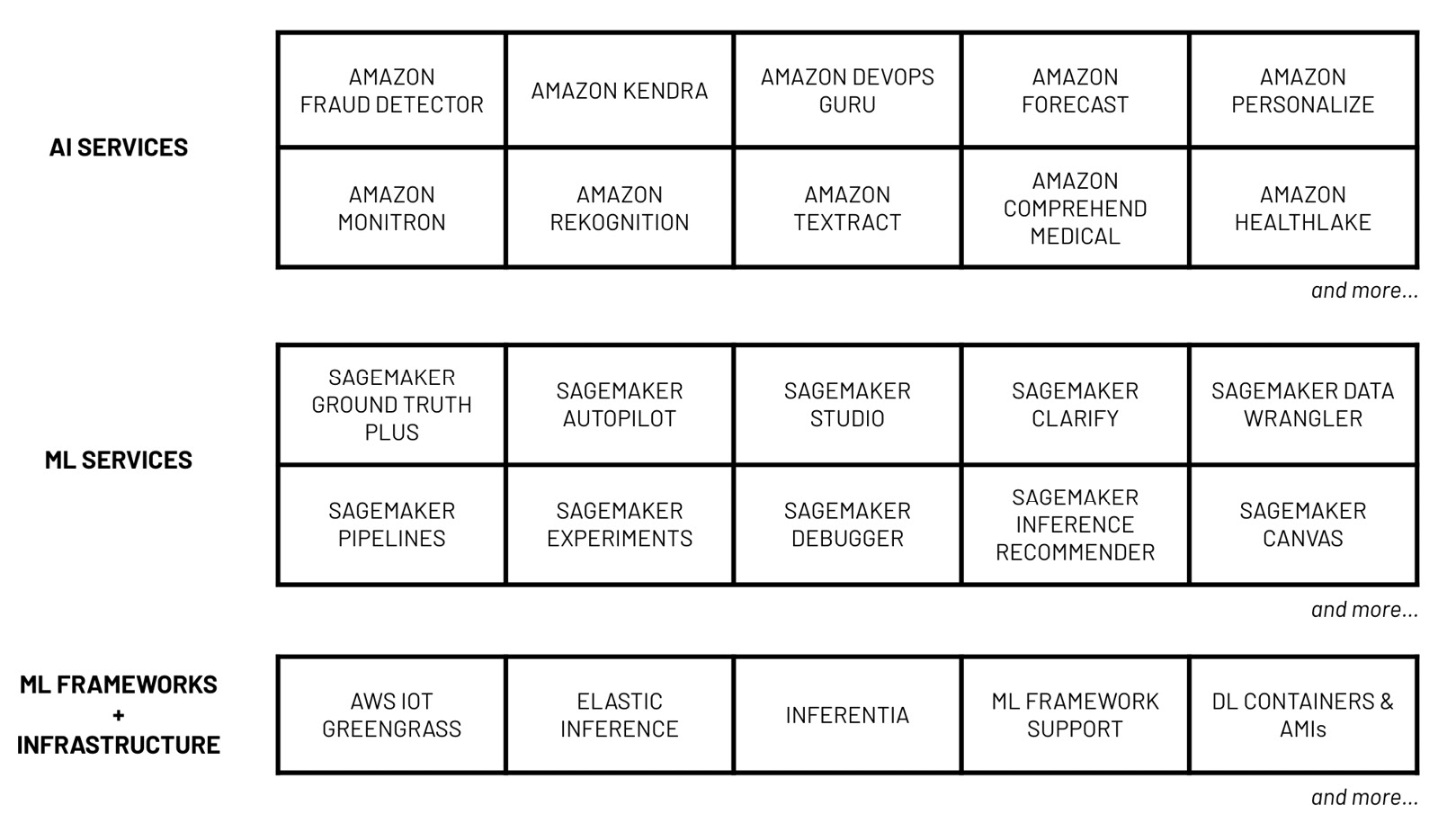
Figure 1.2 – AWS machine learning stack
As shown in the preceding diagram, data scientists, developers, and ML engineers can make use of multiple services and capabilities from the AWS machine learning stack. The services grouped under AI services can easily be used by developers with minimal ML experience. To use the services listed here, all we need would be some experience working with data, along with the software development skills required to use SDKs and APIs. If we want to quickly build ML-powered applications with features such as language translation, text-to-speech, and product recommendation, then we can easily do that using the services under the AI Services bucket. In the middle, we have ML services and their capabilities, which help solve the more custom ML requirements of data scientists and ML engineers. To use the services and capabilities listed here, a solid understanding of the ML process is needed. The last layer, ML frameworks and infrastructure, offers the highest level of flexibility and customizability as this includes the ML infrastructure and framework support needed by more advanced use cases.
So, how can ML engineers make the most out of the AWS machine learning stack? The ability of ML engineers to design, build, and manage ML systems improves as they become more familiar with the services, capabilities, and tools available in the AWS platform. They may start with AI services to quickly build AI-powered applications on AWS. Over time, these ML engineers will make use of the different services, capabilities, and infrastructure from the lower two layers as they become more comfortable dealing with intermediate ML engineering requirements.