-
Book Overview & Buying

-
Table Of Contents

Machine Learning Engineering on AWS
By :
Machine Learning Engineering on AWS
By:
Overview of this book
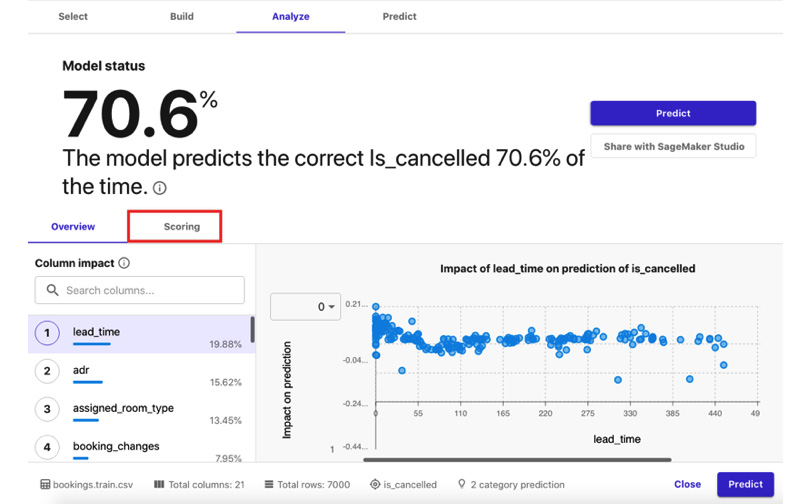
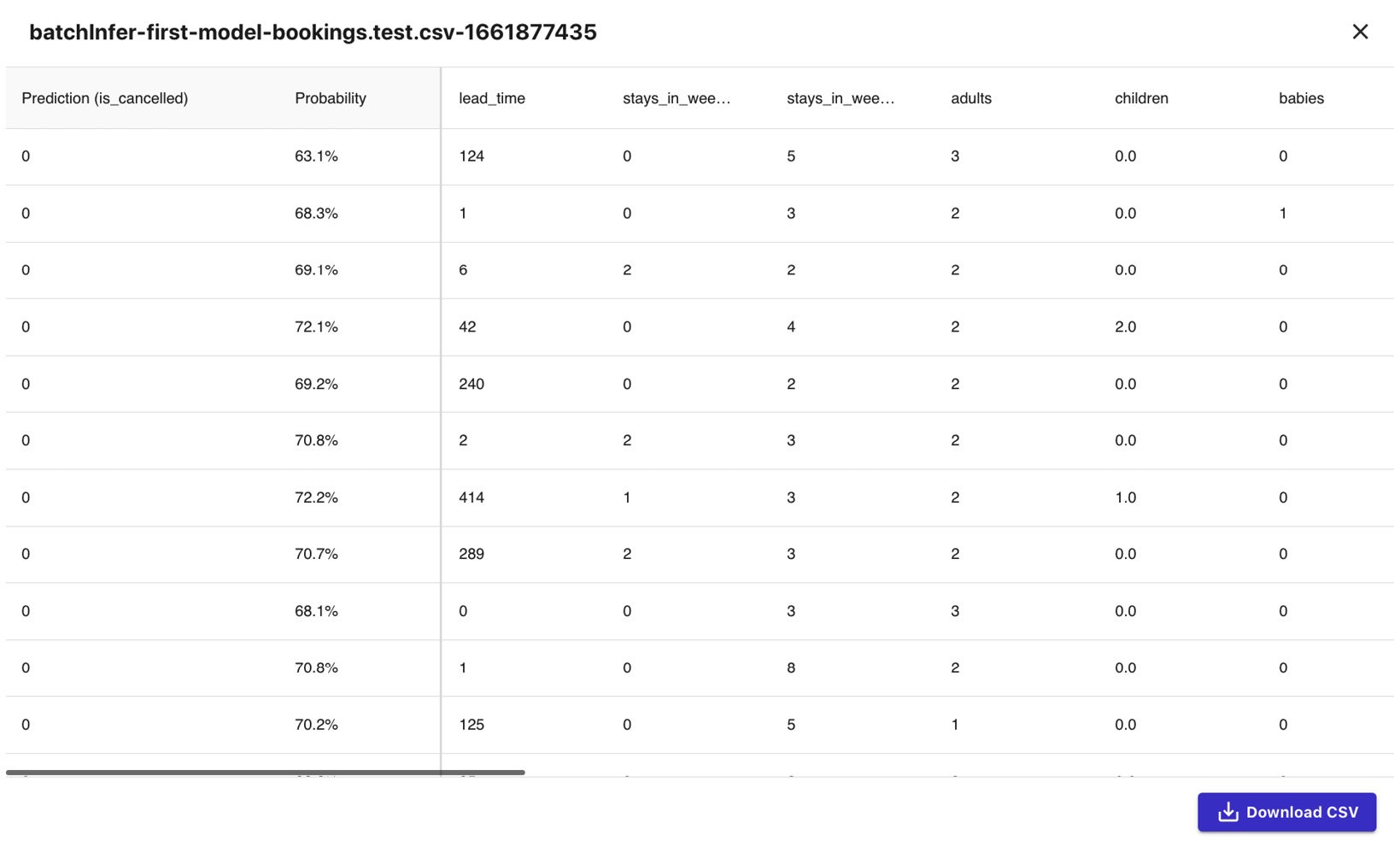
There is a growing need for professionals with experience in working on machine learning (ML) engineering requirements as well as those with knowledge of automating complex MLOps pipelines in the cloud. This book explores a variety of AWS services, such as Amazon Elastic Kubernetes Service, AWS Glue, AWS Lambda, Amazon Redshift, and AWS Lake Formation, which ML practitioners can leverage to meet various data engineering and ML engineering requirements in production.
This machine learning book covers the essential concepts as well as step-by-step instructions that are designed to help you get a solid understanding of how to manage and secure ML workloads in the cloud. As you progress through the chapters, you’ll discover how to use several container and serverless solutions when training and deploying TensorFlow and PyTorch deep learning models on AWS. You’ll also delve into proven cost optimization techniques as well as data privacy and model privacy preservation strategies in detail as you explore best practices when using each AWS.
By the end of this AWS book, you'll be able to build, scale, and secure your own ML systems and pipelines, which will give you the experience and confidence needed to architect custom solutions using a variety of AWS services for ML engineering requirements.
Table of Contents (19 chapters)
Preface

Part 1: Getting Started with Machine Learning Engineering on AWS
 Free Chapter
Free Chapter
Chapter 1: Introduction to ML Engineering on AWS
Chapter 2: Deep Learning AMIs
Chapter 3: Deep Learning Containers
Part 2:Solving Data Engineering and Analysis Requirements
Chapter 4: Serverless Data Management on AWS
Chapter 5: Pragmatic Data Processing and Analysis
Part 3: Diving Deeper with Relevant Model Training and Deployment Solutions
Chapter 6: SageMaker Training and Debugging Solutions
Chapter 7: SageMaker Deployment Solutions
Part 4:Securing, Monitoring, and Managing Machine Learning Systems and Environments
Chapter 8: Model Monitoring and Management Solutions
Chapter 9: Security, Governance, and Compliance Strategies
Part 5:Designing and Building End-to-end MLOps Pipelines
Chapter 10: Machine Learning Pipelines with Kubeflow on Amazon EKS
Chapter 11: Machine Learning Pipelines with SageMaker Pipelines
Index
Other Books You May Enjoy