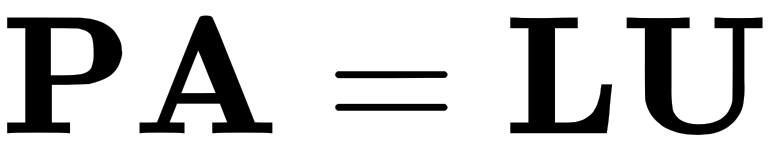Now that we understand how to solve systems of linear equations of the type  where we multiplied a matrix with a column vector, let's move on to dealing with the types of operations we can do with one or more matrices.
where we multiplied a matrix with a column vector, let's move on to dealing with the types of operations we can do with one or more matrices.
-
Book Overview & Buying

-
Table Of Contents

Hands-On Mathematics for Deep Learning
By :
Hands-On Mathematics for Deep Learning
By:
Overview of this book
Most programmers and data scientists struggle with mathematics, having either overlooked or forgotten core mathematical concepts. This book uses Python libraries to help you understand the math required to build deep learning (DL) models.
You'll begin by learning about core mathematical and modern computational techniques used to design and implement DL algorithms. This book will cover essential topics, such as linear algebra, eigenvalues and eigenvectors, the singular value decomposition concept, and gradient algorithms, to help you understand how to train deep neural networks. Later chapters focus on important neural networks, such as the linear neural network and multilayer perceptrons, with a primary focus on helping you learn how each model works. As you advance, you will delve into the math used for regularization, multi-layered DL, forward propagation, optimization, and backpropagation techniques to understand what it takes to build full-fledged DL models. Finally, you’ll explore CNN, recurrent neural network (RNN), and GAN models and their application.
By the end of this book, you'll have built a strong foundation in neural networks and DL mathematical concepts, which will help you to confidently research and build custom models in DL.
Table of Contents (19 chapters)
Preface
Section 1: Essential Mathematics for Deep Learning
 Free Chapter
Free Chapter
Linear Algebra
Vector Calculus
Probability and Statistics
Optimization
Graph Theory
Section 2: Essential Neural Networks
Linear Neural Networks
Feedforward Neural Networks
Regularization
Convolutional Neural Networks
Recurrent Neural Networks
Section 3: Advanced Deep Learning Concepts Simplified
Attention Mechanisms
Generative Models
Transfer and Meta Learning
Geometric Deep Learning
Other Books You May Enjoy
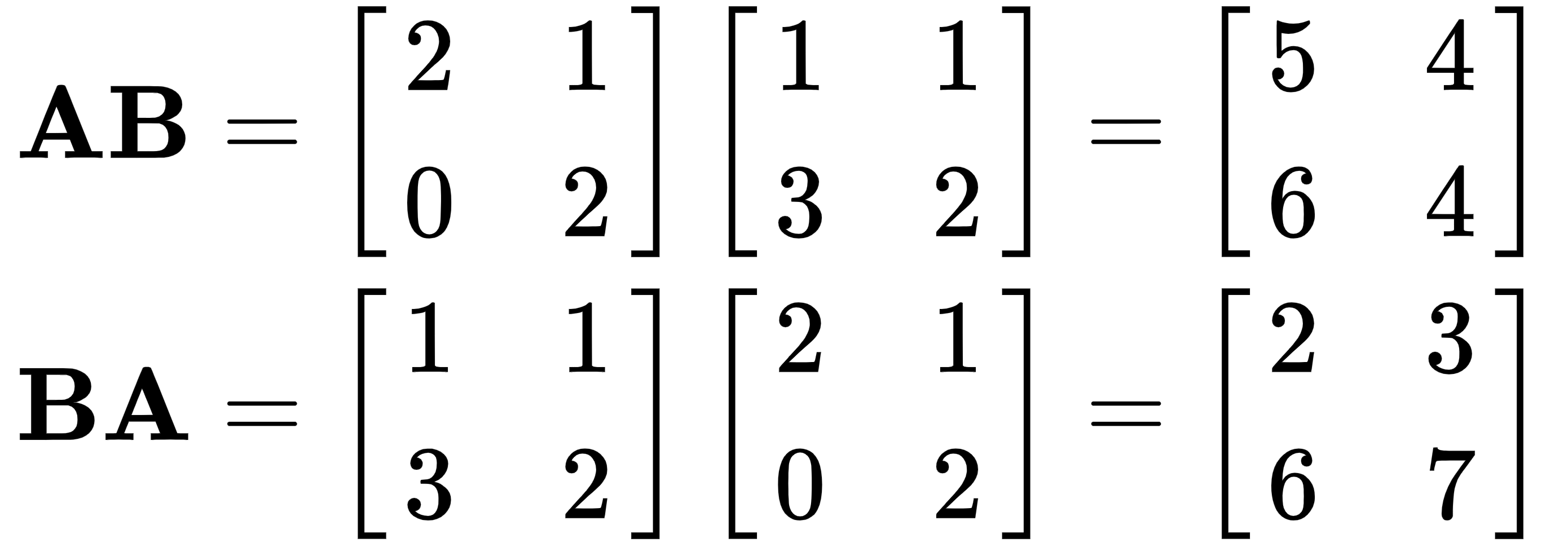
 matrices, A and B, and add them:
matrices, A and B, and add them:
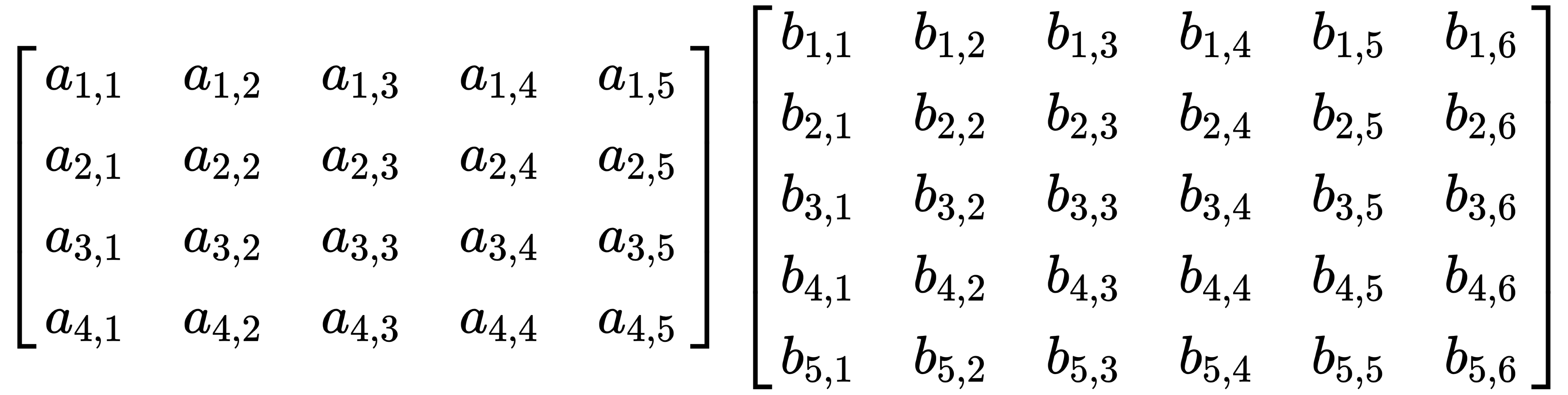
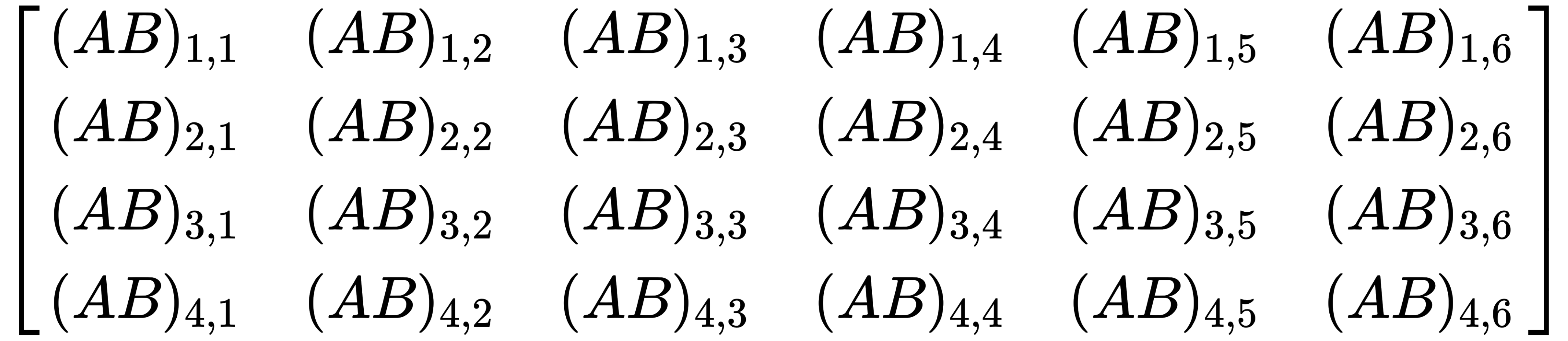
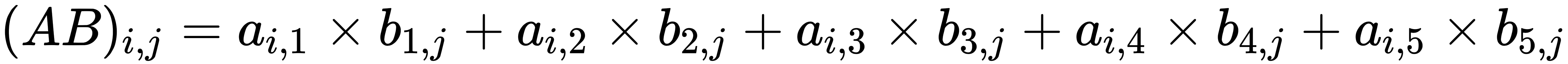
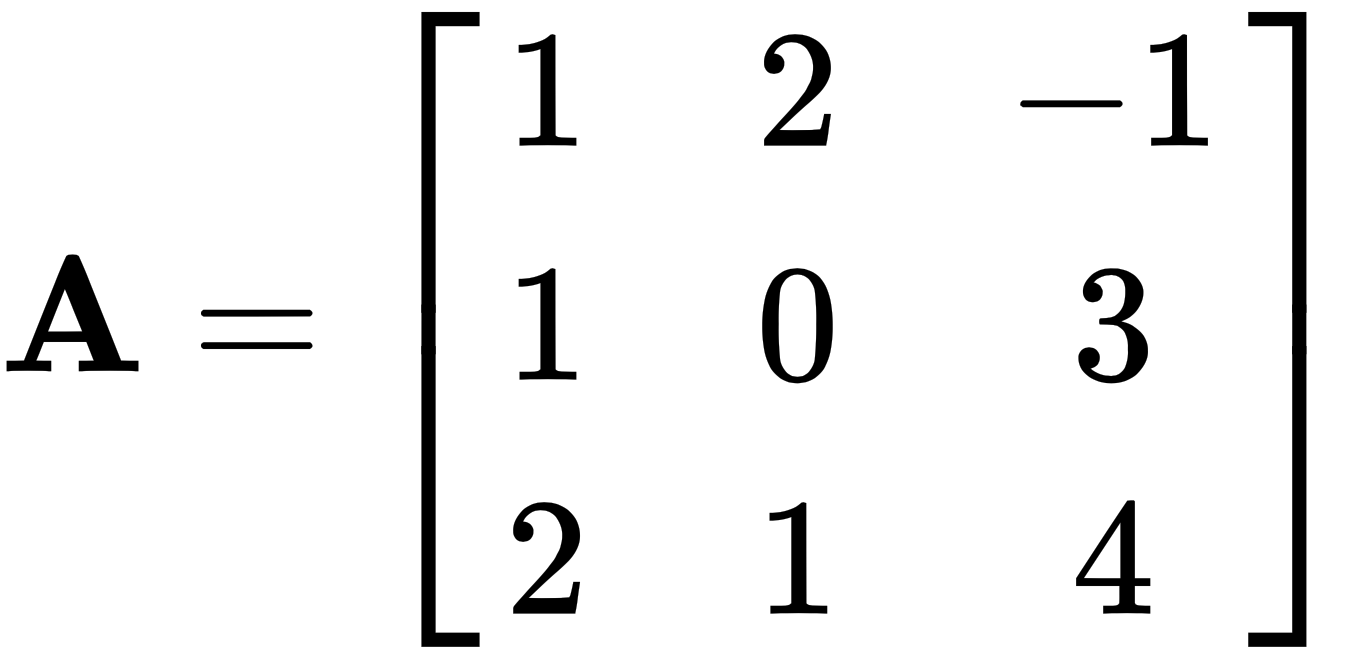 and
and 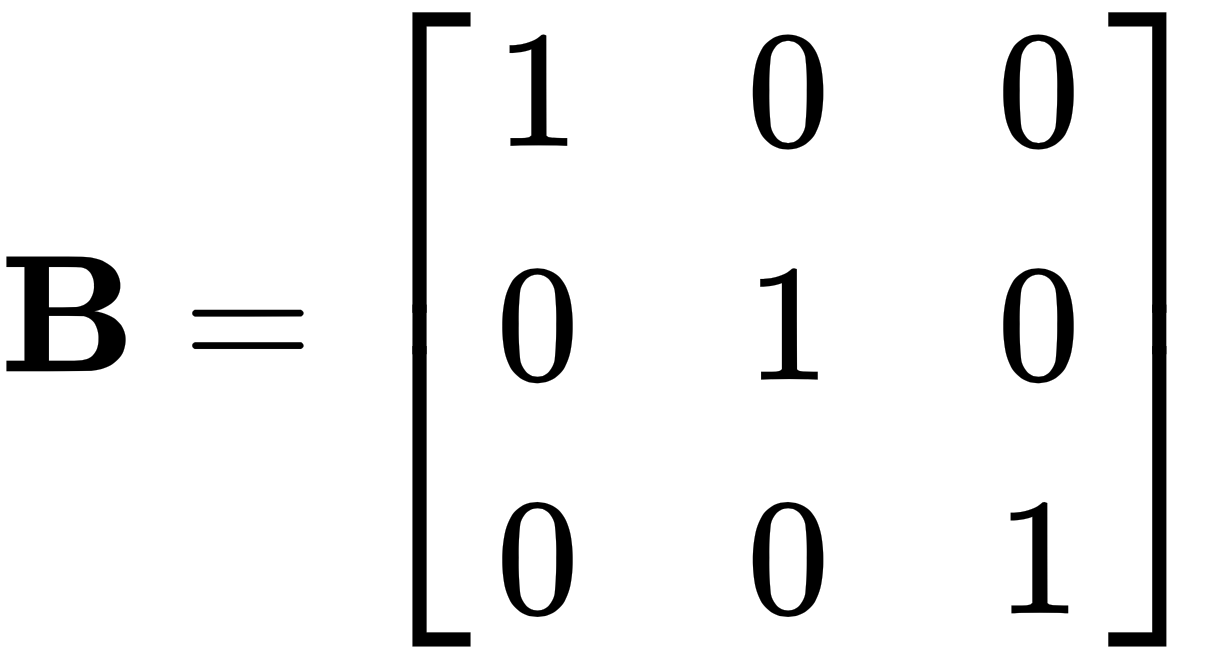
 .
.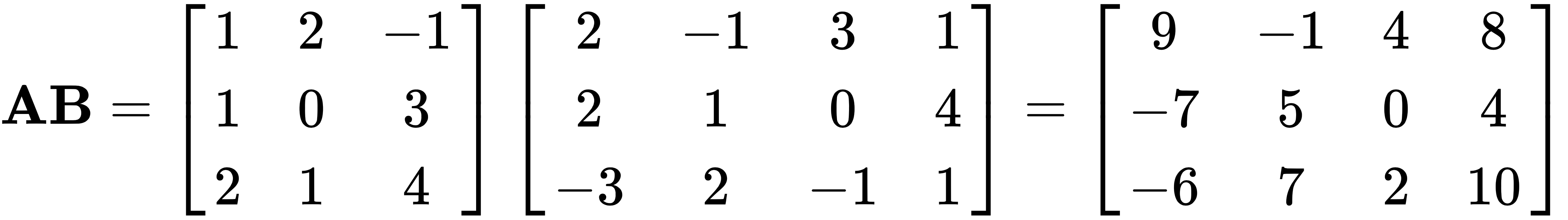
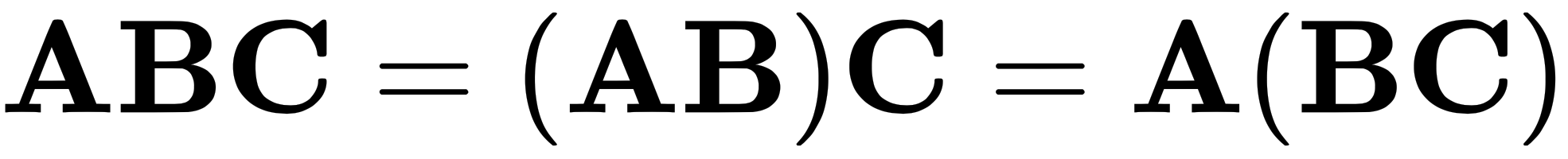

 or
or 

 (multiplying the matrix by itself p times)
(multiplying the matrix by itself p times) and
and  .
.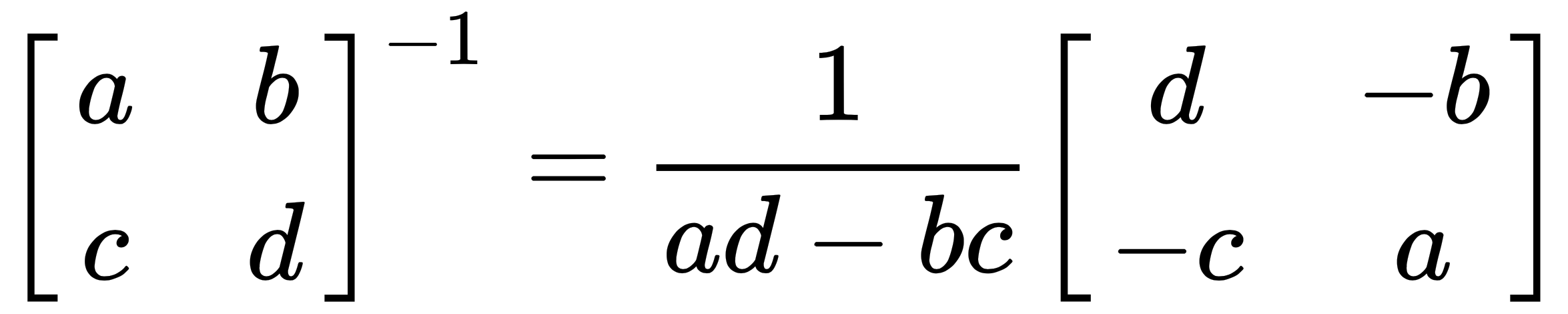
 so that
so that  .
. matrix A. If the matrix's transpose is B, then the dimensions of B are
matrix A. If the matrix's transpose is B, then the dimensions of B are  , such that:
, such that:  . Here is the matrix A:
. Here is the matrix A:
 .
.





 This matrix makes no change to the matrix it is applied on.
This matrix makes no change to the matrix it is applied on. This matrix swaps rows two and three of the matrix it is applied on.
This matrix swaps rows two and three of the matrix it is applied on. This matrix swaps rows one and two of the matrix it is applied on.
This matrix swaps rows one and two of the matrix it is applied on. This matrix shifts rows two and three up one and moves row one to the position of row three of the matrix it is applied on.
This matrix shifts rows two and three up one and moves row one to the position of row three of the matrix it is applied on. This matrix shifts rows one and two down one and moves row three to the row-one position of the matrix it is applied on.
This matrix shifts rows one and two down one and moves row three to the row-one position of the matrix it is applied on. This matrix swaps rows one and three of the matrix it is applied on.
This matrix swaps rows one and three of the matrix it is applied on. and it is invertible, then there exists a permutation matrix that when applied to A will give us the LU factor of A. We can express this like so:
and it is invertible, then there exists a permutation matrix that when applied to A will give us the LU factor of A. We can express this like so: