

The impossibility of complete testing
Let’s say for a moment you are hired by a company that is implementing palindrome software. The Executive Vice President (EVP) for new business explains that the software represents a huge contract with the Teachers Union of Canada, the first of many. As such, there must be no risk within the product. None. To make sure there is no risk, the software must be tested completely.
What is the EVP asking for?
Let’s see just how many risks a palindrome has, starting with the first test that is not completely obvious: uppercase letters. We’ll start by typing a capital B for Bob in the text box and clicking SUBMIT (https://www.xndev.com/palindrome).
This run of the code tells us that Bob is not a palindrome, because Bob is not the same as boB. To someone with a writing background, this might be a bug, because it bugs them. However, to the programmer who wrote the software, the feature is working as designed. All the software does is reverse the thing and compare it, and it shows that Bob and boB are different. This is an especially interesting bug because the programmer and some customers disagree on what the software should do. This type of problem can be addressed earlier through communication and conversation – finding a bug like this so far along means fixing the code and retesting. Possibly, it also means a long series of discussions, arguments, and conflict, ending in no change. Once the end customer sees the software, the team might face another set of arguments. Getting involved earlier and working together to create a shared understanding of what the software should do are helpful things. We’ll touch on them in Part 3, Practicing Politics. For now, our focus is testing, and the product owner was convinced that the simple reversal comparison was good enough.
Speaking of testing, if you run the software on a mobile device such as a phone or tablet, the first letter of the word is capitalized. To make most palindromes work, the user has to downshift the first letter every time. This might be a bug. And certainly, mobile devices should be tested. This means duplicating every test in four platforms, including Chrome, Firefox, Safari (Mac), or Edge (Windows) for each of the five devices, including laptop, tablet, and perhaps three or four different phones, which makes it five combinations in each of the Linux, Mac, and PC ecosystems (three combinations). This means you don’t run one test – you run 60 (4*5*3). An argument can be made that the underlying technology of these is norming, so there is much less risk. Yet once you see the combinatorics problem in one place, you’ll see it everywhere – for example, with versions of the Android operating system and mobile devices.
Meanwhile, we’ve barely scratched the surface of palindromes. An experienced tester will, at the very least, test spaces (if you do, you’ll find multiple spaces at the front or back are truncated) and special characters such as !@#$%^&*()<>,/?[]{}\|; they are likely to test embedding special characters that might have meaning under the hood, such as database code (SQL), JavaScript, and raw HTML. An open question is how the browser handles long strings. One way to test this is to go to Project Gutenberg (https://www.gutenberg.org/, an online library of free electronic books, or eBooks, most of which are in the public domain), find a large bit of text, then search for a string reversal tool online. Next, you can add the first string to the reversed second one and run it. A good open question is, How large a string should the code accept?
Strings are collections of text. At the time of writing, when you google classic palindrome sentence, the first search results include the following:
- Mr. Owl ate my metal worm
- Do geese see God?
- Was it a car or a cat I saw?
All of these will fail in the palindrome converter because they are not the same forward and backward. A literature review will find that a palindrome sentence is allowed to have capitalization, punctuation, and spaces that are ignored on reversal.
Did anyone else notice the Anagram section at the bottom of the page shown in Figure 1.1? All that functionality is part of the next release. Anyone testing it is told to “not test it” and “not worry about it” because it is part of the next release. Yet unless the tester explicitly reminds the team, that untested code will go out in the next build!
We could also check all these browsers and devices to see if they resize appropriately. We haven’t considered the new challenges of mobile devices, such as heat, power, loss of network while working, or running while low on memory. If you are not exhausted yet, consider one more: just because a test passes once does not mean it will pass the next time. This could be because of a memory leak or a programmer optimization. As a young programmer, Matt once wrote a joke into a tool called the document repository, where there was a 1% chance it would rename itself on load, picking a random thesaurus entry for document and one for repository. A graphic designer, offended by the term Archive Swag Bag, insisted Matt change it. He replied, “Just click refresh.” While the story was based on a joke from the game Wizardry V, it did happen. This kind of problem does happen in software – for example, in projects that store frequently used data and have a longer lookup for rare data. Errors can happen when the data is read from longer-term storage and when it is written out, and when those happen can be unpredictable.
Now, consider that this is the code for the palindrome that is doing all the heavy lifting:
original = document.getElementById("originalWord").value;
var palindrome = original.split("").reverse().join("");
if ( original === palindrome) {
document.getElementById("palindromeResult").innerHTML = "Yes! " + original + " reversed is " + palindrome;
} else {
document.getElementById("palindromeResult").innerHTML = "No! " + original + " reserved is " + palindrome;
} All these tests are for one textbox, one button, six lines of code, and one output. Most software projects are considerably more complex than this, and that additional complexity adds more combinations. In many cases, if we double the size of the code, we don’t double the number of possible tests; we square the number of possible tests.
Given an essentially unlimited input space and an unlimited number of ways to walk through a dynamic application, and that the same test repeated a second time could always yield different results, we run into a problem: complete testing is impossible.
Note
One of our earlier reviewers, Dr Lee Hawkins, argues that we haven’t quite made our point that complete testing is impossible. So, here’s mathematical proof:
1. We must consider that the coverage of our input space is a function, such as f(x)
2. A demonstration of f(n) does not demonstrate that f(n+1) is correct
3. A complex test would test from f(orig) to f(∞)
4. If f(n) does not imply f(n+1), proof by induction is impossible
5. If the input space goes to f(∞), or infinity, dynamic testing is impossible
Thus, complete testing is impossible.
As complete testing is impossible, we are still tasked with finding out the status of the software anyway. Some experts, people we respect as peers, say this cannot be done. All testing can do is find errors. The best a tester can say is, “The software appeared to perform under some very specific conditions at some specific point in time.”
Like happy path testing, anyone can do and say that. It might technically be true, but it is unlikely to be seen as much more than a low-value dodge.
When Matt was a Cadet in the Civil Air Patrolin Frederick Composite Squadron, there was a scroll that hung on a nail in the cadet office. This is what it said:
That is what we are tasked to do: the impossible for the (often) ungrateful. By this, we mean that we must find the most powerful tests that reveal the most information about the software under test and then figure out what information the tests reveal.
Part of doing that is figuring out for ourselves, in our project, where the bugs come from so that we can find them in their lair with minimal effort.
If you aren’t convinced yet, well, we ran out of room – but consider the number of combinations of possible tests in a calculator. Now, consider if the calculator might have a small memory leak, and try to detect that leak with tests. Complete testing is impossible. Say it again: complete testing is impossible.
Before we move on to a theory of error, we hope you’ve explored the software yourself and have a list of bugs to write up. Save them and use Chapter 5 to practice writing them up. Our favorite defect is likely HTML injection; you can use an IMG tag or HR tag to embed HTML in the page.
Toward a theory of error
When people talk about bugs in software, they tend to have one root cause in mind – the programmer screwed up. The palindrome problem demonstrates a few types of a much wider theory of error. A few of these are as follows:
- Missed requirement: It would be really easy to do an operation I logically want to do… but there is no button for it.
- Unintended consequences of interactions between two or more requirements: On the Mars rover project, one input took meters and the other yards. Those measurements are close, but they don’t work for astrophysics.
- Common failure modes of the platform: On a mobile app, losing internet signal or a draining battery is suddenly a much bigger deal.
- Vague or unclear requirements: “The input device” could be a keyboard, a mouse, or a Nintendo Wii controller.
- Clear but incorrect requirements: “Yes, we said it should do that. Now that we’ve seen it, we don’t like it.”
- Missed implicit requirements: Everyone just knows that the (F)ile menu should be the first in an editing program, with (N)ew immediately below that and (C)lose at the bottom.
- Programmer error: This is the one we understand and tend to assume.
- The software doesn’t match customer expectations: Imagine building and testing the Anagram function as if it were written for elementary English teachers to use with students, when in fact it was for extremely picky Scrabble players – or the other way around. This might bug someone, or a group large enough to matter. Thus requirements and specifications are less what the software will do, and more a generally shared agreement as to what the software should do, made at some point in time.
Even this quick, sloppy list is much wider and deeper than the idea of the simple happy path of testing the obvious. The list is sloppy by design. Instead of presenting it as final, we suggest that, over time, testers build their own lists. More important than the list are the things in the list, and the weights attached to them – that is, the percentage of effort that corresponds to each category of error. Once you have a list and have gone past the happy path and requirements-driven approaches, you can create scenarios that drive the software to where these failures might be. Those are tests.
The list of categories, what is in them, and their weights will change over time as you find more bugs, and as the technical staff, product, and platform change. Our goal with this book is to accelerate that learning process for you and provide ideas that help you develop those powerful test ideas.
Testing software – an example
There are plenty of books that say the person doing the testing should be involved up-front. Our example will go the other way. In this example, the software engineering group does not create the “consistent, correct, complete, clear” requirements that are idealized. Their requirements did not decompose nicely into stories that have clear acceptance criteria that can be objectively evaluated. The stories did not have a “kick-off” meeting where the developers, the person doing testing, and the product owner got together to build a shared mental model.
Instead, someone plunked us down at a keyboard and said, “Test this.” As an example, we can use the old Grand Rapids Airport Parking Calculator, which, at the time of writing, Markus Gärtner has copied and placed on his website at https://www.shino.de/parkcalc/. Looking at the following figure; it is a piece of software that allows you to predict the cost of your airport parking:
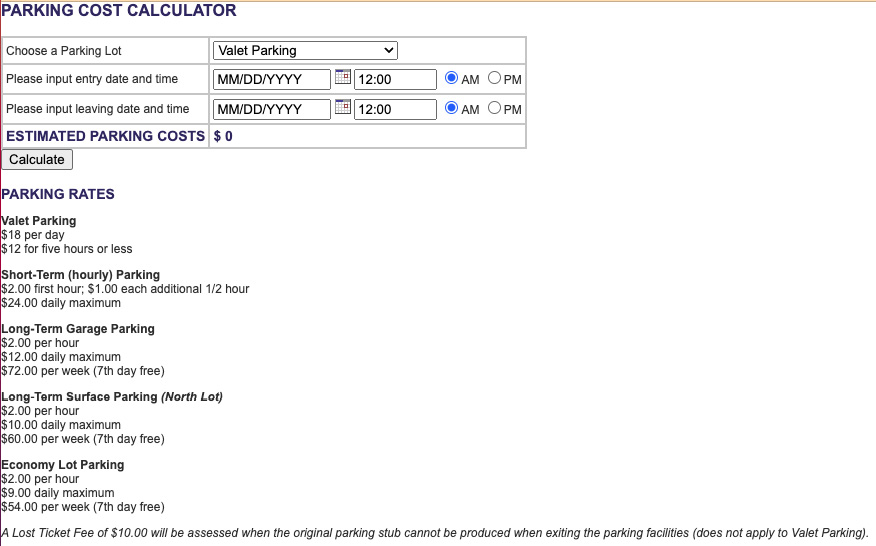
Figure 1.2 – ParcCalc from Markus’s website
The techniques we are about to list have been quickly determined and are rapid-fire, with questions to learn how they behave under different conditions. This thinking applies to unit tests, specialized tests, application programming interface (API) tests, and other risk management approaches. As Matt tested ParkCalc seriously for the first time in years, he wrote down what he was thinking and doing; you could look at it almost like a chess game that was documented for your benefit.
During testing, he was asking questions about the software, as an attorney might ask a suspect under examination in court. The answers led him to the next question. Instead of trying to build the software up, as a programmer does, he was trying to figure out what makes it work, a different style of thought. This thinking can apply to requirements, the API’s performance, or accessibility.
Start of test notes
This is a little more complex than a palindrome – more inputs, more outputs, and many more equivalence classes, which are categories to break things into that “should” be treated the same. We might hypothesize, for example, that the difference between 10/1/2024 at 1:05 P.M. and 10/1/2024 at 1:07 P.M. is not worth testing. This shrinks the number of potential tests a bit as we can test one thing for the “bucket” of, say, 1 minute to 59 minutes. Boundary values point out that the errors tend to be around the transitions – at 59 minutes, 60, or 61. This happens when a programmer types, for example, less than (<); in this case, they should type less than or equal to (<=). These are sometimes called off-by-one errors. Unit tests, which we’ll explore later, can radically decrease how often these sorts of errors occur. For now, though, we don’t know if the programmers wrote unit tests.
When we run these sorts of simulations, it’s common for the person performing the test to want to get the customer involved, to get some sort of customer feedback, or to try some sort of mind-meld with the product owner. These approaches can be incredibly powerful, and we’ll discuss them in this book, particularly in the Agile testing section. For now, however, we’ll strip everything down to the raw bug hunt. This is unfair for many reasons. After all, how can you assess if the software is “good enough” if no one tells you what “good enough” means?
And yet we press on...
In this example, we have a single screen and a single interaction. Later in this book, in Chapter 9, we’ll talk about how to measure how well the software is tested when it is more complex. For now, the thing to do is “dive in.” The place to dive in with no other information is likely the user interface. When Markus created the page, he did us the great favor of adding requirements in the text below the buttons. Note those requirements hinge on “choose a parking lot,” which is the first drop-down element:
|
A software tester walks into a bar: They run into it They crawl into it. They dance into it They fly into it They jump into it |
The tester orders: A beer 2 beers 0 beers 999,999,999 beers A goldfish in a beer glass (test: water or beer?) -1 beer A “qwerty” beers |
The tester declares that testing is complete |
A real customer walks into the bar and asks where the bathroom is The bar goes up in flames |
Table 1.1 – A tester’s view of the world
Faced with an interface like this, I tend to interleave two ideas: using the software while overwhelming the input fields with invalid, blank, out-of-range, or nonsensical data. This provides a quick and shallow assessment. The tradeoff here is coverage (checking all the combinations) with speed (getting fast results).
So, when I tested it at the time of writing, these tests looked like this:
|
Test Number |
Type |
Date Start |
Date End |
Time Start |
Time End |
Expected |
|
1 |
Valet |
7/29/22 |
7/29/22 |
2:00 P.M. |
3:00 P.M. |
$12.00 |
|
2 |
Valet |
7/22/22 |
7/22/22 |
2:00 P.M. |
7:00 P.M. |
$12.00 |
|
3 |
Valet |
7/22/22 |
7/22/22 |
2:00 P.M. |
7:01 P.M. |
$18.00 |
Table 1.2 – Valet parking test examples
You can build a similar table like this for your tests:
|
Test Number |
Type |
Date Start |
Date End |
Time Start |
Time End |
Expected |
|
4 |
Valet |
7/29/22 |
7/29/22 |
2:00 P.M. |
2:59 P.M. |
$12.00 |
Table 1.3 – Sample table for your own tests
Now, we find a second issue. After we return to the main page, the drop box defaults back to Valet. This means the correct dollar amount shows, but it looks to the reader like it was selected for valet parking.
At this point, I started clicking the calendar to find the datetime picker:
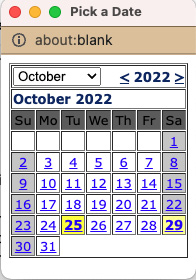
Figure 1.3 – Datetime picker
Notice that the picker says about:blank, which likely means an optional parameter for about is not populated. Beyond that, if you click away from the picker and back to the page, it gives the page focus. In older browser versions, the popup would not stay at the front focus but would stay behind the page with focus. This is fixed in current browsers. This led to testing maximizing the page and filling the entire screen.
Another bug is that, if the screen is maximized and you click the popup, it appears as a strange maximized new tab:

Figure 1.4 – Maximized new tab.The intent of this screenshot is to show the maximized layout; text readability is not required.
If you start to look at the requirements, you’ll see a lot of valid combinations for each type. We could decompose all the possibilities. When you look at that appendix, you will realize that the list is just too long. Exploring short-term just a little more yields these combinations:
30 minutes, 60 minutes, 90 minutes, 120 minutes, 121 minutes, 119 minutes 23 hours and 59 minutes, 24 hours, 24 hours and 1 minute
Leap years. Three interesting ideas to test are to see if the datetime picker realizes that 2024 contains February 29 but 2023 and 2022 do not, to see if the tool correctly realizes that February 28 to March 1 2023 is 1 day in 2023 and 2 days in 2024, and to hard-code, say, 2/29/2023 to 3/1/2023 as a date and see if the software realizes the date is in error.
While the first two scenarios work, the period from 2/29/2023 at 14:00 to 3/1/2023 at 13:59 seems to be -1 days, 23 hours, and 59 minutes. This is the same calculation as 3/1/2023 to 3/1/2023 14:00 to 13:59. The software seems to be calculating the date as days_since_something; numbers beyond the end of the month just get added on. Also, if you think about it, “-1 days PLUS 23 hours PLUS 59 minutes” is the same as 0 days, 0 hours, and -1 minutes:
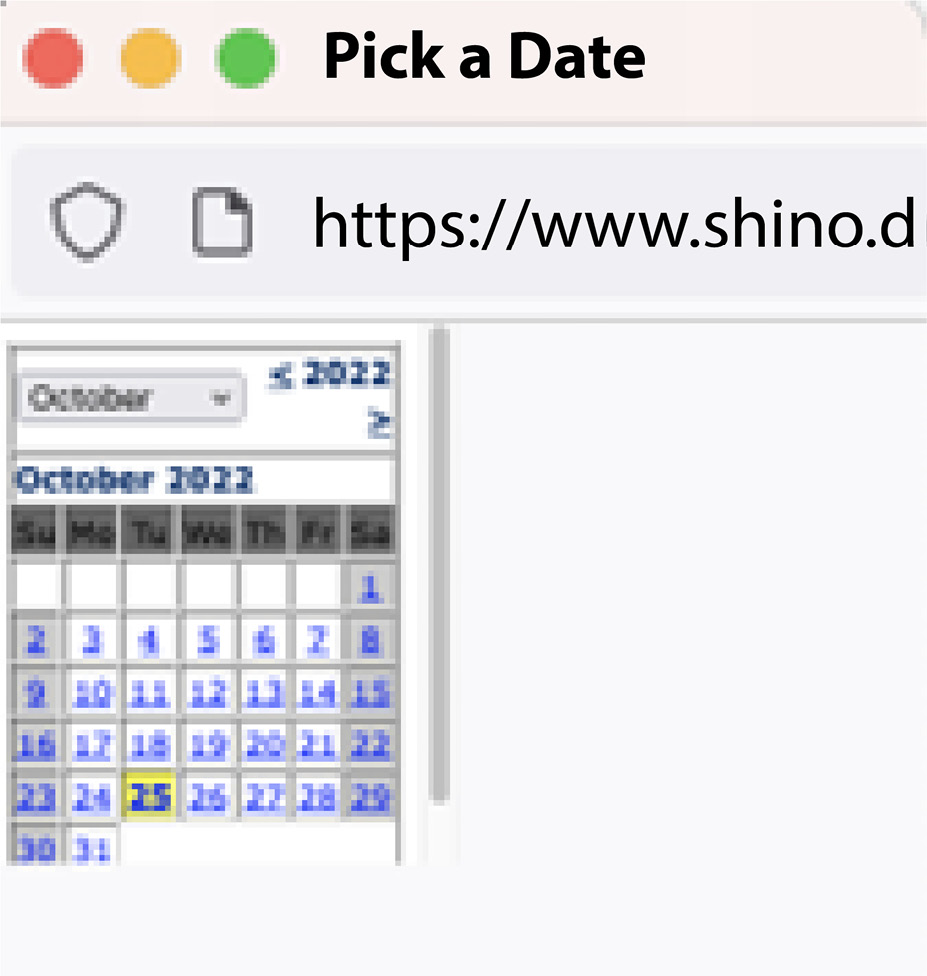
Figure 1.5 – Highlighted date picker
While this is probably a bug, exactly how the software should work is a little less clear. It might be better to print an error message, such as Departure date from parking cannot be before arrival.
My next move is to switch over to Firefox and mess with the popup. On two monitors, I see the popup appear in the center of my first monitor, apparently with fonts selected for the second. I also see the same maximize causes popup to open in a new tab problem.
Note that today’s date appears in the date picker with a yellow background. If the month has 31 days in it, then the last day is also yellow. Why we would want that, I’m not sure. I moused over the button to find the name of the JavaScript function, which is NewCal(). Then, I right-clicked and chose View source to find the web page code. Not finding a definition for NewCal in the source, I found the following include, which pointed to the JavaScript file name that might include NewCal:
<script language="JavaScript" type="text/JavaScript" src="datetimepicker.js"></script>
Looking at that code (https://www.shino.de/parkcalc/datetimepicker.js) it appears to be someone else’s custom date time picker, not anything from the operating system. Here’s the beginning of the source code:
//Javascript name: My Date Time Picker //Date created: 16-Nov-2003 23:19 //Scripter: TengYong Ng //Website: http://www.rainforestnet.com //Copyright (c) 2003 TengYong Ng //FileName: DateTimePicker.js //Version: 0.8 //Contact: [email protected]
This code appears to be from 2003 and likely hasn’t kept up as people started to use more monitors, smartphones, and so on. I tried the app on my iPhone and the interface was hard to read, and the date picker was even more awkward. I could have spent a great deal of time looking at this JavaScript code if I wanted to.
With no specific goals on risks or effort, the JavaScript code for DatePicker is just one of many directions I could speed off in, with no plans or governance of where to invest my time. While the things I have found so far bug me, I don’t know that the product owner would care. So, again, I’d try to find a person with the authority to make final decisions to talk about the expectations for the software and test process. This will guide my testing. If I know the decision maker just does not care about entire categories of defects, I won’t waste time testing them. Let’s say the person in charge of the product made a common reasonable decision: “Spend about an hour on a bug hunt, don’t get too focused on any one thing, and then we’ll decide what to do next.”
This statement isn’t that far-fetched. A few years ago, Matt worked with a team that had made a corporate decision not to support tablets for their web application. Of course, the customer used them anyway, to the tune of several million dollars a month and growing exponentially. Instead of saying “We don’t support tablets,” which was no longer a choice, a proposal was made to go into an empty office for a day and figure out what the largest blocking issues were. It might have been that we just needed a half-dozen bug fixes; it might have been so bad that a total rewrite was needed. Without actually using the software on a tablet, no one knew.
Timing work to an hour, it was determined that each action from the dropdown would take about 3 minutes minus 15 minutes total. That would be 15 more minutes for each platform (different browsers, different screen resolutions, different devices), then 15 minutes exploring incorrect data, and 15 minutes to double-check and document findings.
Speaking of overwhelming, the next test is to examine data that looks correct but is not. An example is short-term parking from 10/32/2022 to 11/3/2022, or valet from 12:00 P.M. to 70:00 P.M. Both of those return results that fit the mental model of how the software is performing – that is, the expectation is to convert complex dates into a simpler format and subtract them. 1:00 P.M. becomes 13:00 A.M., so the software can subtract and get elapsed time. Thus, 10/32 is the same as 11/1 and 70:00 P.M. is 10:00 P.M. plus 2 days (48 hours).
It’s time for a new test: I tried short-term, 12:00 A.M. to 13:00 A.M. The time should be 1 hour, and the rate should be $2.00. Instead, the software says $24.00, which is the day-rate maximum. Looking at the time, I can see that this is treated as 12:00 A.M. (midnight) to 1:00 P.M., or 13 hours, at $2.00 per hour, with a daily max of $24.00 – that is, 12:00 A.M. is midnight, to be followed by 12:01 A.M., with 1:00 A.M. 1 hour after midnight.
End of test notes
After a few pages of reading how I test, you’ve probably realized a few things. A lot of details have been included but nowhere near as much as was performed (this example was shortened for printing purposes and yet was still full of information). In the next section, we will break down the steps we performed and analyze how and why we performed the tests listed. Let’s examine what we accomplished here and see how we can use these techniques in our testing process.