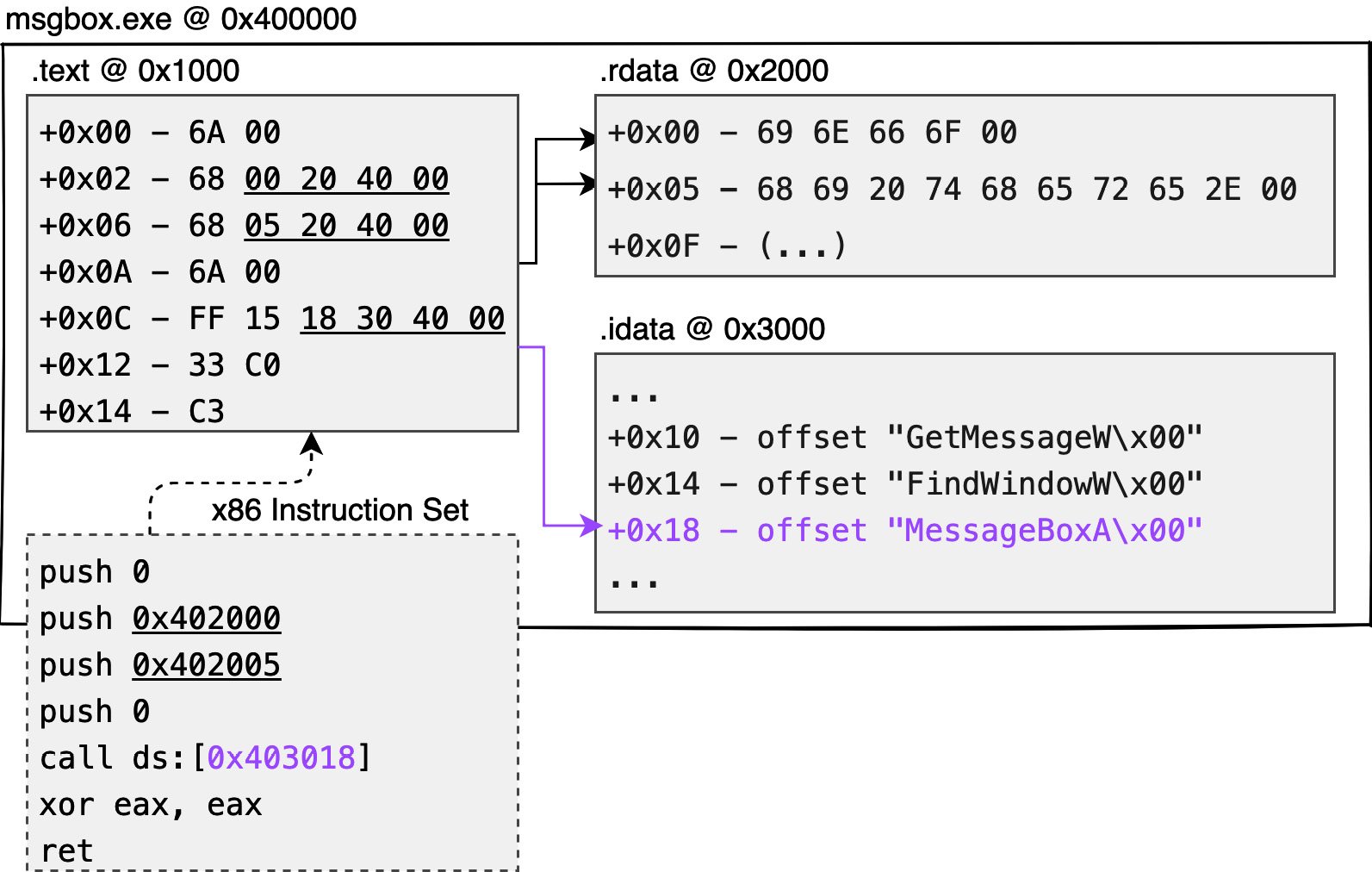
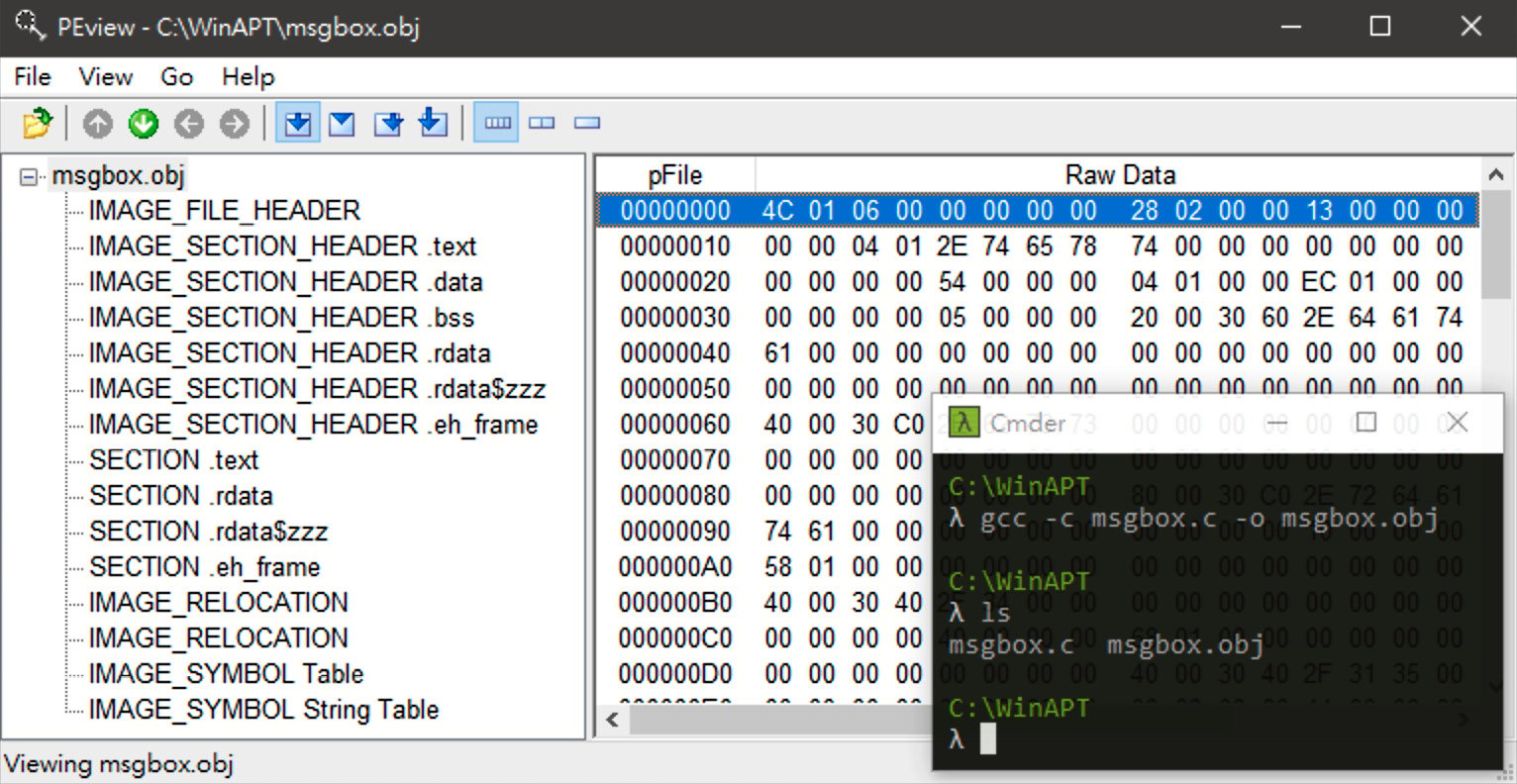
-
Book Overview & Buying

-
Table Of Contents

Windows APT Warfare
By :
Windows APT Warfare
By:
Overview of this book
An Advanced Persistent Threat (APT) is a severe form of cyberattack that lies low in the system for a prolonged time and locates and then exploits sensitive information. Preventing APTs requires a strong foundation of basic security techniques combined with effective security monitoring. This book will help you gain a red team perspective on exploiting system design and master techniques to prevent APT attacks. Once you’ve understood the internal design of operating systems, you’ll be ready to get hands-on with red team attacks and, further, learn how to create and compile C source code into an EXE program file. Throughout this book, you’ll explore the inner workings of how Windows systems run and how attackers abuse this knowledge to bypass antivirus products and protection.
As you advance, you’ll cover practical examples of malware and online game hacking, such as EXE infection, shellcode development, software packers, UAC bypass, path parser vulnerabilities, and digital signature forgery, gaining expertise in keeping your system safe from this kind of malware.
By the end of this book, you’ll be well equipped to implement the red team techniques that you've learned on a victim's computer environment, attempting to bypass security and antivirus products, to test its defense against Windows APT attacks.
Table of Contents (17 chapters)
Preface

Part 1 – Modern Windows Compiler
 Free Chapter
Free Chapter
Chapter 1: From Source to Binaries – The Journey of a C Program
Chapter 2: Process Memory – File Mapping, PE Parser, tinyLinker, and Hollowing
Chapter 3: Dynamic API Calling – Thread, Process, and Environment Information
Part 2 – Windows Process Internals
Chapter 4: Shellcode Technique – Exported Function Parsing
Chapter 5: Application Loader Design
Chapter 6: PE Module Relocation
Part 3 – Abuse System Design and Red Team Tips
Chapter 7: PE to Shellcode – Transforming PE Files into Shellcode
Chapter 8: Software Packer Design
Chapter 9: Digital Signature – Authenticode Verification
Chapter 10: Reversing User Account Control and Bypassing Tricks
Index
Other Books You May Enjoy
Appendix – NTFS, Paths, and Symbols